
Every few months an open model shows up and quietly embarrasses something four times its size. This month it’s HiDream-O1-Image — an 8-billion-parameter image generator that, on five standard benchmarks, beats FLUX.2 [dev] (roughly 32B). It’s MIT-licensed, it runs locally, and it reasons about your prompt before it draws a single pixel.
The Story
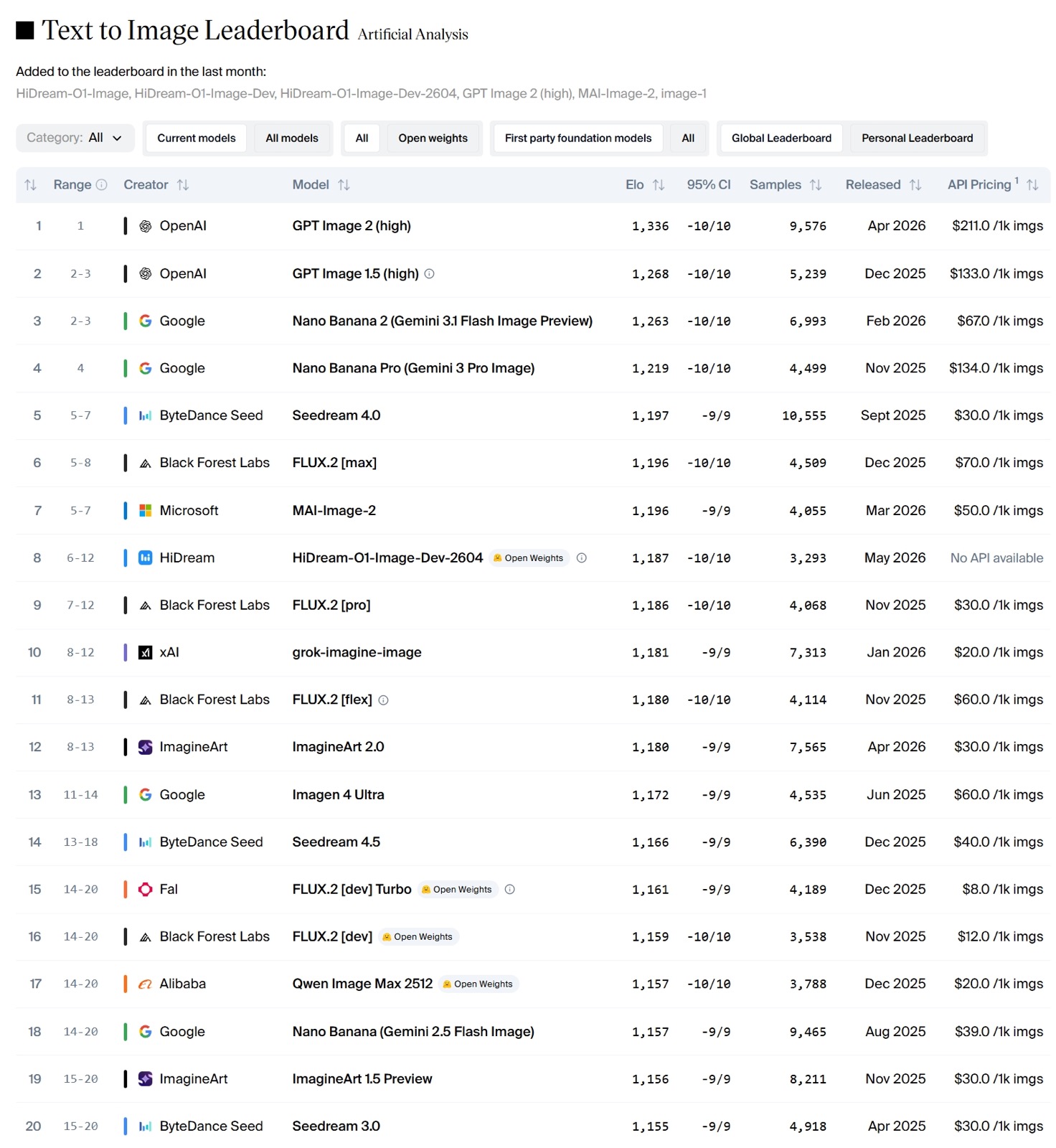
HiDream.ai dropped the weights on May 8, 2026, followed by a distilled “Dev-2604” checkpoint on May 14. The headline number: #8 on the Artificial Analysis Text-to-Image Arena — the highest any open-weights model has ever climbed, sitting in a chart otherwise dominated by closed APIs from Google, OpenAI and ByteDance.
What’s genuinely new is the architecture. Most diffusion models are a stack of bolted-together parts: a VAE to squeeze pixels into latents, a separate text encoder (often CLIP or T5) to read your prompt, and a denoiser in the middle. HiDream-O1 throws that whole pipeline out. It’s a Pixel-level Unified Transformer (UiT) — no external VAE, no disjoint text encoders. Raw pixels, text tokens, and task conditions all live in one shared token space, and the model synthesizes natively at up to 2,048 × 2,048.
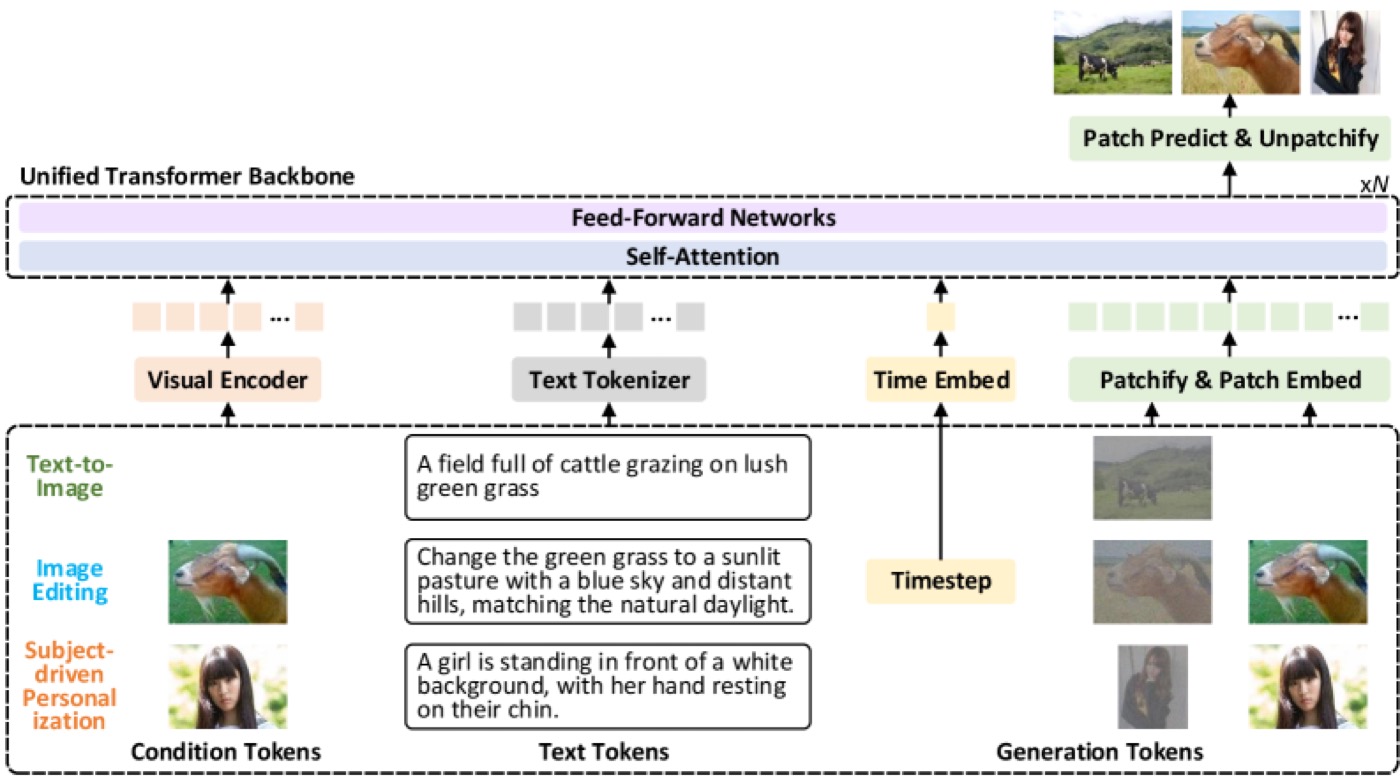
The “O1” in the name is the second trick. Borrowing the chain-of-thought idea from reasoning LLMs, HiDream-O1 runs a Reasoning-Driven Prompt Agent over your prompt first — explicitly working through layout, subject identity, physical logic, text-rendering details and multilingual knowledge, then emitting a structured plan (a rewritten prompt plus its reasoning) before generation begins. You can run that agent locally on a Gemma backend or point it at any OpenAI-compatible endpoint. It’s the same instinct behind the “thinks before it draws” closed models we’ve covered — except here the whole thing is yours to inspect.
Why You Should Care
The benchmark wins aren’t a rounding error. On GenEval (compositional accuracy) it scores 0.90 overall — 0.99 on two-object prompts, 0.93 on positioning — versus 0.87 for FLUX.2 [dev]. On DPG-Bench it hits 89.83 against FLUX.2’s 87.57. And on LongText-Bench, the thing every designer secretly cares about, it lands 0.979 EN / 0.978 ZH — crushing FLUX.2’s 0.757 on Chinese text rendering.

For creative technologists, the practical wins stack up fast:
- It fits on real hardware. 8B means a 24GB card runs it; quantized community builds push it lower. No 32B-class GPU rental.
- MIT license. Commercial use, fine-tuning, redistribution — no usage gate, no API meter.
- One model, six jobs. Text-to-image, instruction editing, multi-reference subject personalization, pose/skeleton control, layout control, and storyboard generation all live in the same checkpoint.
- Text that actually reads. Multi-region, multilingual signage and UI mockups without the usual gibberish.
Honest caveat: it’s a foundation model with no RLHF or aesthetic fine-tuning, so out of the box it favors accuracy over the glossy, opinionated look of Midjourney. That’s a feature if you’re building pipelines and a quirk if you want hero shots with zero prompt work — expect to lean on the prompt agent or your own LoRAs.
Try It / Follow Them
- No-install test: the official Hugging Face Space runs it in the browser.
- Weights & code: model card on Hugging Face and the GitHub repo (inference scripts, the
prompt_agent.py, and a Gradio web demo). - Run the Dev variant (28 steps instead of 50) for faster local generation; quantized GGUF-style builds are already up from the community.
- The paper: arXiv 2605.11061 for the UiT and O-Voxel-free pixel-space details.
- Watch: ComfyUI native support landed in the v0.22 cycle — expect node workflows within days if not already live.
IK3D Lab Take
The interesting part isn’t that an open model topped the open-weights chart again — that happens. It’s how. HiDream-O1 is two bets at once: collapse the diffusion pipeline into a single pixel-native transformer, and bolt an explicit reasoning pass onto the front of image generation. Both are directions the closed labs are clearly heading too — but HiDream shipped the weights, MIT-licensed, for anyone to dissect. For a 3D-and-creative-tech crowd, the immediate payoff is a genuinely capable, locally-runnable base model that does editing, subject consistency and readable text in one place — exactly the parts that break ControlNet-and-duct-tape ComfyUI graphs today. Grab the Space, throw a hard compositional prompt at it, and see whether “reasoning before drawing” earns its name. We think it does.



