Every 3D generation model you know uses diffusion. FLUX, Stable Diffusion 3D, Shap-E, Point-E — they all start from noise and iteratively refine. GaussianGPT from TU Munich just threw that playbook out and did something nobody expected: it generates 3D Gaussian scenes token by token, exactly like ChatGPT writes text.
The Story
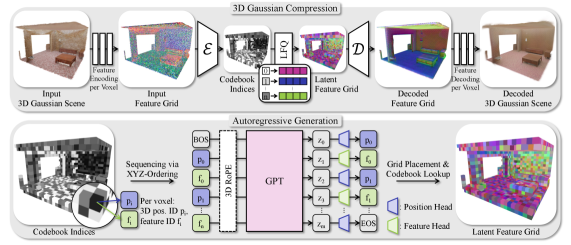
Researchers at TU Munich’s Visual Computing Lab — Nicolas von Lutzow, Barbara Rossle, Katharina Schmid, and Matthias Niessner — published GaussianGPT in late March 2026. The core idea: compress a 3D Gaussian Splatting scene into discrete tokens via a sparse 3D convolutional autoencoder with vector quantization, then model those tokens with a GPT-2-scale causal transformer using 3D Rotary Positional Embeddings (3D RoPE). The model generates scenes voxel by voxel — predicting first where geometry is, then what it looks like.
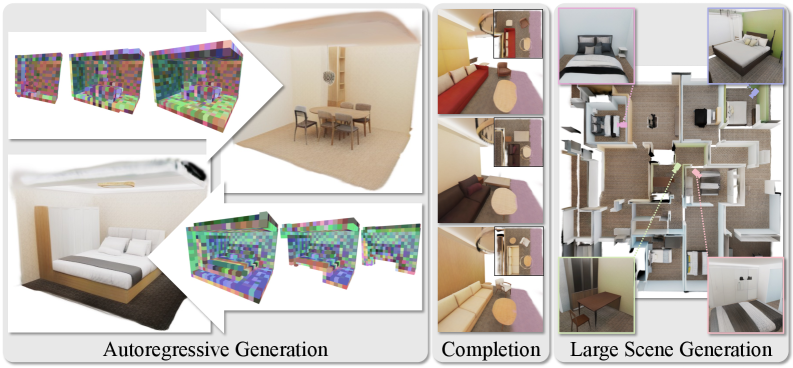
This is fundamentally different from diffusion. Diffusion models start from pure noise and iteratively denoise. GaussianGPT builds from scratch, one spatial chunk at a time. The consequence is a set of capabilities diffusion models struggle with:
- Scene completion: Give it a quarter of a room, it fills in the rest.
- Outpainting: Extend a 4mx4m scene to 12mx12m via sliding context window.
- Temperature-controlled sampling: Dial up creativity or stay faithful to context.
- Variable generation length: Stop early for a rough sketch, run longer for detail.
Why You Should Care
The 3D generation space has been almost entirely owned by diffusion since 2022. GaussianGPT demonstrates there is a viable alternative paradigm — one that plays to the unique strengths of Gaussian Splatting. Diffusion generates holistically: the whole scene at once. Autoregressive generation is compositional — it builds piece by piece, which means you can pause and steer mid-scene, complete partially-observed spaces, or generate arbitrarily large environments via sliding window.
For VFX artists, architects, and game developers, this distinction matters. You don’t want a model that hallucinates an entire environment from scratch — you want one that can logically extend what you’ve already built, or fill in gaps from a lidar scan. The outputs are native 3DGS scenes you can drop into Gaussian Splat Studio, SuperSplat, or Unreal directly. No conversion. No re-export.


Try It / Follow Them
- Paper: arXiv 2603.26661
- Project page + demo videos: nicolasvonluetzow.github.io/GaussianGPT
- Code: GitHub (Coming Soon — watch the repo)
The project page demo videos are worth your time — especially the completion video where the model reconstructs a full room from a corner slice. Matthias Niessner is one of the most cited researchers in 3D reconstruction; his group does not publish vaporware.
IK3D Lab Take
The real shift here is conceptual. For three years, the question in 3D generation has been: “how do we make diffusion work better in 3D?” GaussianGPT asks a different question: what if we applied the architecture that made language models great? The fact that it works — and produces coherent results on indoor scenes, real-world ScanNet data, and large synthetic environments — suggests this is a genuine research direction, not just an academic exercise.
The code is coming soon. When it drops, this will be worth running if you have the GPU headroom. If you are building AI-augmented workflows around 3D scenes — in Blender, Unreal, or your own pipeline — this is the paper to bookmark this month. The completion and outpainting capabilities open up workflows that simply do not exist yet for working artists and developers. Watch this space.



