A research lab you’ve probably never heard of just dropped a fully open-source, 15-billion parameter model that generates photorealistic, lip-synced talking head videos in 2 seconds on a single H100 — and it beats D-ID, Ovi, and LTX in head-to-head comparisons. Apache 2.0. Free. No strings.

The Story
Sand.ai and SII-GAIR Lab — a Chinese AI research organization — quietly published a paper titled “Speed by Simplicity” and released the entire model stack on Hugging Face and GitHub in late March 2026. No fanfare, no paid tier. Just the weights, the code, and a benchmark table that would make most commercial vendors sweat.
The model is called daVinci-MagiHuman, and it does one thing extremely well: take a reference image of a person, a text prompt, and optionally audio — and generate a synchronized, expressive talking head video that looks and sounds completely natural.
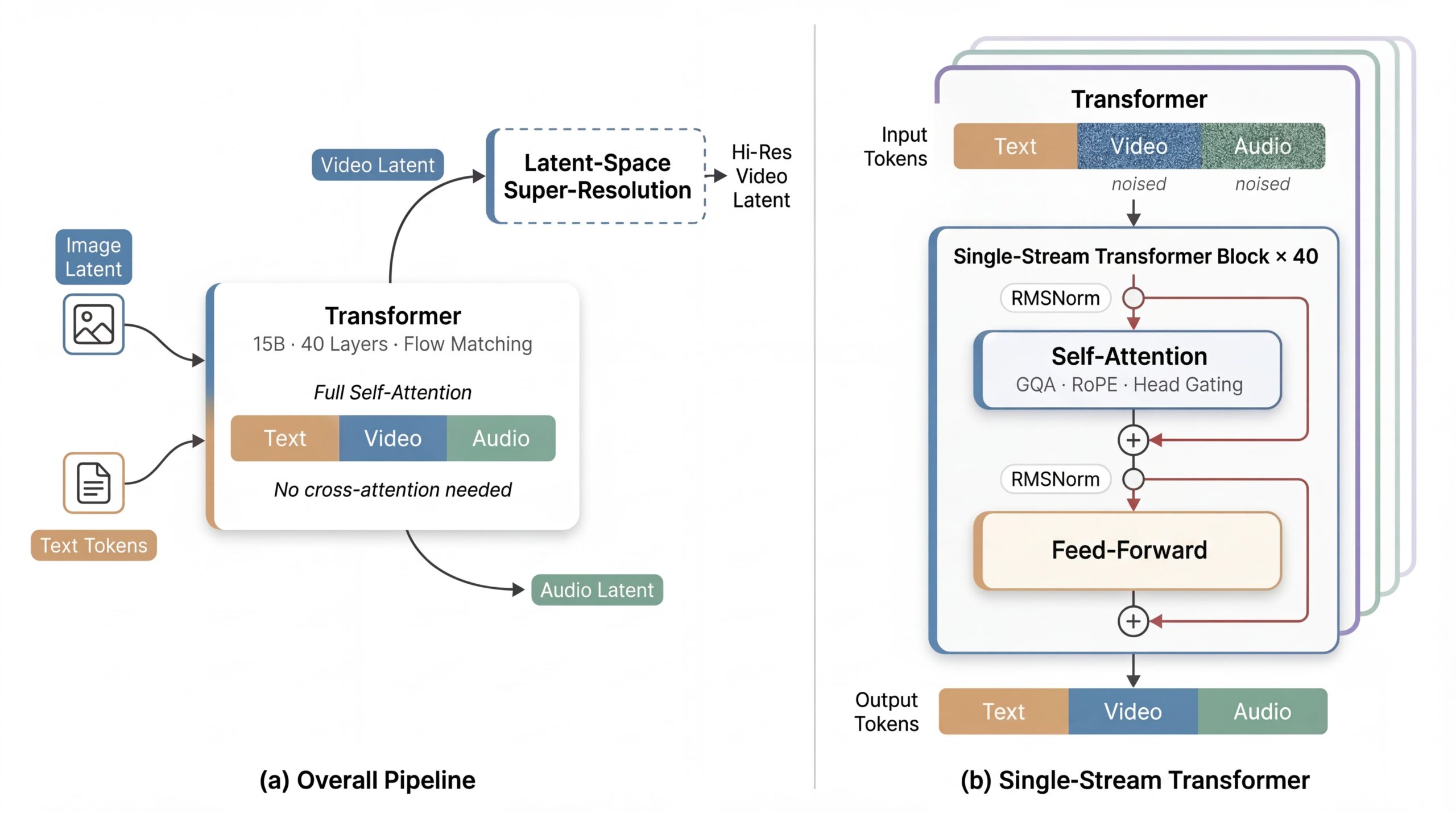
What makes it technically interesting isn’t just the quality. It’s the architecture. Most audio-video generation models are complex multi-stream systems — separate encoders for video, audio, and text, stitched together with cross-attention. daVinci-MagiHuman throws all of that out and uses a single unified 15B-parameter Transformer that processes everything — text tokens, reference image latents, noisy video tokens, and audio tokens — in one shared token sequence via pure self-attention.
The team calls it a Sandwich Architecture: the first and last 4 layers handle modality-specific projections, while the middle 32 layers share all parameters across modalities. No explicit timestep embeddings, no dedicated conditioning branches. The model infers the denoising state directly from the input latents. Fewer moving parts = faster training, faster inference, easier optimization.
The Numbers Are Hard to Ignore
The benchmark results tell the story better than marketing copy ever could. Against two of the most capable open-source alternatives — Ovi 1.1 and LTX 2.3 — daVinci-MagiHuman was put through 2,000 pairwise comparisons rated by 10 human evaluators:
- 80.0% win rate vs Ovi 1.1
- 60.9% win rate vs LTX 2.3
On automatic evaluation, it achieves the lowest Word Error Rate of any open model tested: 14.60% vs Ovi 1.1’s 40.45% and LTX 2.3’s 19.23%. In practical terms: when it makes someone speak, you can actually understand what they’re saying.

And then there’s the speed. On a single H100:
- 256p, 5-second video: 2.0 seconds total
- 540p, 5-second video: 8.0 seconds total
- 1080p, 5-second video: 38.4 seconds total
That 256p speed — a 5-second clip in 2 seconds — is approaching real-time territory. For prototyping, demo generation, or batch workflows, that’s game-changing.
Why You Should Care
The digital human/talking head space has been dominated by commercial platforms — D-ID, HeyGen, Synthesia — that charge per-minute, lock output quality behind paywalls, and require you to upload your content to their servers. The open-source alternatives have historically been noticeably worse in quality and reliability.
daVinci-MagiHuman changes that calculus significantly. If you can access an H100 (via Hugging Face Spaces, RunPod, or similar cloud services), you now have access to a talking head model that:
- Beats commercial products on quality benchmarks
- Is fully open-source under Apache 2.0 — use it commercially, fork it, fine-tune it
- Speaks 7 languages: Chinese (Mandarin + Cantonese), English, Japanese, Korean, German, French
- Can be self-hosted — your data never leaves your environment
For 3D artists and game developers: imagine scripting a dialogue scene, dropping in character reference images, and having lip-synced performance previews generated in seconds — before you even open your rigging tool. For architects: AI-narrated walk-throughs of your renders, no voice actor needed. For digital storytellers: consistent character performance across scenes without motion capture.

Try It / Follow Them
The full stack is live right now:
- Hugging Face Demo: spaces/SII-GAIR/daVinci-MagiHuman — no install required, run in browser
- Model Weights: huggingface.co/GAIR/daVinci-MagiHuman
- GitHub + Code: github.com/GAIR-NLP/daVinci-MagiHuman
- Paper: arXiv:2603.21986 — “Speed by Simplicity”
- ComfyUI integration: Already in progress at ComfyUI-DaVinci-MagiHuman
The ComfyUI wrapper is still a work-in-progress, but the official Hugging Face Space works now. Python 3.12+ and PyTorch 2.10+ for local runs. Requirements aren’t trivial — the base model is 15B — but distilled models are included in the release for faster inference on less monstrous hardware.
IK3D Lab Take
The thing that’s most exciting about daVinci-MagiHuman isn’t any single capability — it’s the combination of open weights + state-of-the-art quality + Apache 2.0 license. That combination didn’t exist in the talking head space until now.
The simplified architecture is also a signal worth paying attention to. The field has been trending toward massive multi-component pipelines, and here’s a paper saying “we threw all that out, used one big Transformer, and won.” That’s the kind of architectural insight that tends to propagate fast.
The ComfyUI integration is the one to watch. Once that’s stable, this model drops into every existing AI art workflow with zero friction. Character sheets to animated dialogue, concept to performance — inside the same tool you’re already using for everything else. That’s when this gets really interesting for the creative community.
Sand.ai and SII-GAIR didn’t just publish a paper. They gave the creative tech community a weapon.



